2、垃圾收集器
2、垃圾收集器
垃圾收集器的目标就是为了减少STW而努力。
2.0 CMS
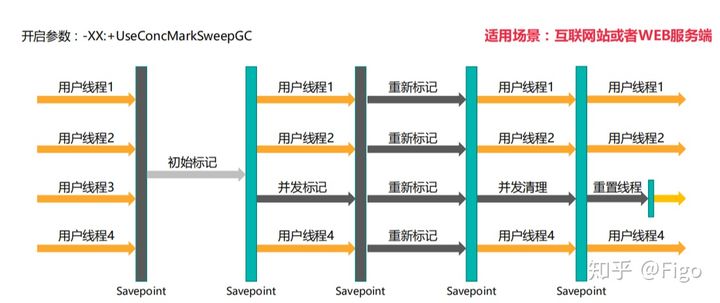
是一种以获取最短回收停顿时间为目标的收集器。这个收集器也是基于标记-清除算法实现的,他的运作过程相比前面几种收集起来说要更复杂一些,整个过程分为四个步骤。
初始标记
并发标记
重新标记
并发清除
初始标记也需要,所有用户线程停顿,然后标记出GCROOT能直接关联到的对象。速度很快,并发标记就是开始搜索全图,此时不需要用户线程停顿。重新标记是为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录。这时也需要停止用户线程。然后进行并发清除。
缺点:
1.CMS收集器对处理器资源非常敏感
2.无法处理浮动垃圾(就是并发清理阶段生成的垃圾)
后备预案,冻结用户线程的执行,临时启用Serial Old收集器来重新进行老年代的垃圾收集。
2.1 G1
JDK9之后G1成了默认的垃圾收集器
G1的几种分区
年轻代(Eden区和Survivor区)
自由代
老年代
大对象区
每个Region的大小通过-XX:G1HeapRegionSize来设置,大小为1~32MB,默认最多可以有2048个Region,那么按照默认值计算G1能管理的最大内存就是32MB*2048=64G。
因为我们每个区域的Region的大小可以自己设定,然后我们设定超过一半Region大小的对象为大对象,则放入大对象分区中,另外就是当超过几个Region的对象,我们可以通过大对象分区的几个Region进行存储。
另外因为传统的垃圾回收器的停顿时间是不可预估的,所以不是特别好,所以我们可以通过G1来对停顿时间进行一个预估,我们可以通过回收之后的空间大小、回收需要的时间,根据评估得到的价值,在后台维护一个优先级列表,然后基于我们设置的停顿时间优先回收价值收益最大 的Region。
G1里新生代的大小,占所有空间的 5%,最大可以拓展到 60 %。
新生代的大小,主要通过这几个参数决定。
G1NewSizePercent、G1MaxNewSizePercent固定新生代大小。
-XX:NewRatio看看是否设置了比值,新生代和老年代的比值
如果没有则按之前的比例,5% - 60%
回收过程
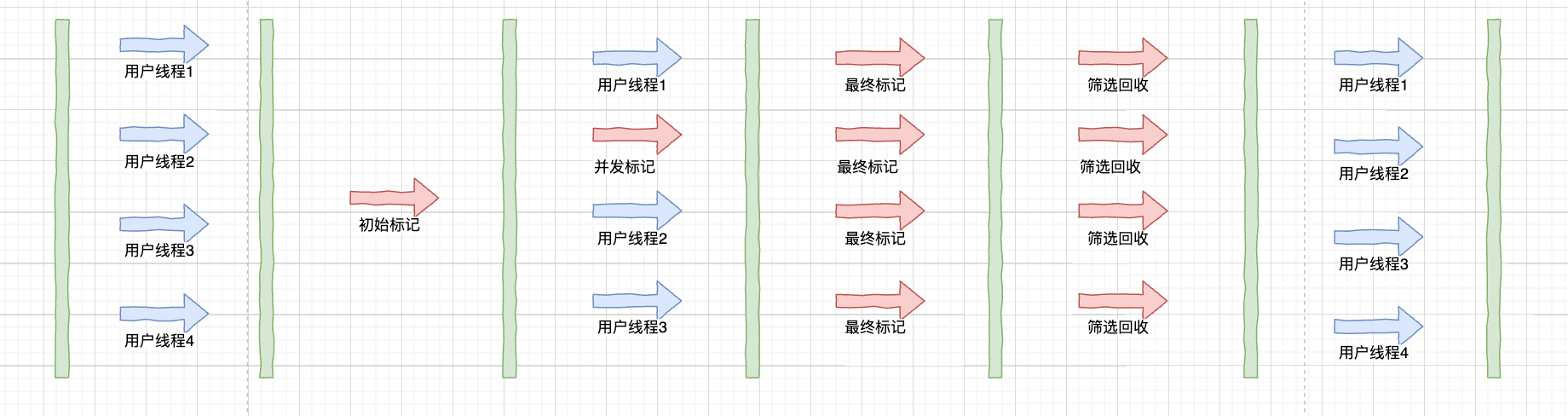
初始标记:GC ROOT能关联到的对象需要可达性分析
并发标记:不需要停止,标记整个对象图中所有对象,并且会标记上并发过程中产生的新对象。
最终标记:需要STW,做最后一次标记
筛选回收:通过获取的最大收益进行回收。然后把需要回收的Region中,存活的对象复制到新的Region中。
新生代的回收情况:会回收新生代eden区的内容,当里面含有存活的对象时,将其复制到 Survior 中,使其年龄+1,如果年龄超过阈值,则将其复制到老年代中。
eden 和 Survivor的 比例大概是 8:1:1,因为百分之 90 的新生代都是朝生夕死,然后8+1用来回收新生代,另一个 1 用来复制。
2.2 其他垃圾收集器
Serial
最基础,历史最悠久的垃圾收集器,是一个单线程工作的收集器,他在收集垃圾时,必须暂停其他工作,直到它收集结束。新生代标记-复制,老年代标记-整理
Serial old
是Serial的老年代版本,使用标记-整理算法,主要有两种用法,一种是和Parallel Scavenge 搭配使用,另一种是作为CMS的预案。
ParNew收集器
和Serial 收集器相比,没有太大改进,仅仅是增加了多线程回收,然后新生代使用复制算法回收,老年代采用标记整理回收,后面ParNew和CMS垃圾收集器配合使用,作为新生代的收集器。
Parallel Old
是 Parallel Scavenge 的老年代版本,支持多线程并发收集,基于标记整理算法啊。
Parallel Scavenge
这个收集器也是一款新生代收集器,同样是基于标记-复制算法实现的收集器。它和其他收集器不同的地方是,他专注于可以达到一个可以控制的吞吐量。
吞吐量 = 运行用户代码时间/(运行用户代码时间+运行垃圾收集时间)
高吞吐量,适合在后台运算而不需要太多交互的分析任务。自适应调整策略是这个收集器的一个重要特性。
