2、应用层
2.应用层
HTTP
2.0 HTTP 状态码
| 状态码 | 类别 | 原因短语 |
|---|---|---|
| 1XX | 信息性状态码 | 接收的请求正在处理 |
| 2XX | 成功状态码 | 请求正常处理完毕 |
| 3XX | 重定向状态码 | 需要进行附加操作以完成请求 |
| 4XX | 客户端错误状态码 | 服务端无法处理请求 |
| 5XX | 服务端错误状态码 | 服务端处理请求出错 |
301:永久重定向
302:临时重定向
400:语法错误
401:表示需要认证
403:表示请求被拒绝
404:没发现资源
500:服务器内部出现故障
503:服务器正在维护,或者已经超载
推荐阅读:https://www.runoob.com/http/http-status-codes.html
2.1 HTTP长连接和短链接
短链接:每进行一次HTTP通信,就要断开一次TCP连接
持久连接:建立一次TCP连接后进行多次请求和响应的交互。
Connection:keep-alive
推荐阅读:https://www.cnblogs.com/cswuyg/p/3653263.html
2.2 GET 和 POST 请求方式对比
Http 常用的请求方法共有 8种,
- 在HTTP1.0中,定义了三种请求方法:
GET, POST 和 HEAD方法。 - 在HTTP1.1中,新增了五种请求方法:
OPTIONS, PUT, DELETE, TRACE 和 CONNECT方法 但我们常用的一般就是GET和POST请求。
我们常用的主要有两种。
GET,POST他们两个的不同
GET有长度限制
POST 比GET安全,因为 url GET是直接暴露的。POST数据不会显示在URL中,是放在Request body中。
参数类型,GET只支持ASCLL码,POST没有要求。
GET请求会保存在浏览器记录里,POST浏览器也不会保存。
GET只支持url 编码,POST 则没有限制
GET会被浏览器主动缓存,POST则不会
GET回退是无害的,POST则是再次发出请求。
GET有没有Request Body 呢?
因为 GET是直接暴露在外面的,但是浏览器对url的大小限制为 2K,所以如果长度太大,也就是 url 参数较多,则有可能不被接收。
有人说POST 比 GET安全,这是因为 POST 在地址栏,url是看不到的其实在http 中,他们两个都是不安全的,因为 HTTP 是明文传输。
GET 和 POST 请求发送的数据包有什么不同?
GET是一个包将Header 和 body 同时发送过去,POST 是先发送head ,再发送body,分两个包发送。
就像是GET只需要汽车跑一趟就把货送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼老铁,我等下要送一批货来,你们准备接收一下哈,然后再回头把货送过去。
推荐阅读:https://www.zhihu.com/question/28586791/answer/1890418047
2.3 HTTP 1.1
HTTP1.0和HTTP1.1的一些区别
HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。 主要区别主要体现在:
缓存处理
,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。带宽优化及网络连接的使用,错误通知的管理
,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。长连接
,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。压缩报文Host头处理
,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
HTTP 2.0
二进制编码:HTTP/2 厉害的地方在于将 HTTP/1 的文本格式改成二进制格式传输数据,极大提高了 HTTP 传输效率,而且二进制数据使用位运算能高效解析,这里一句话总结就是,将侦使用二进制格式传输。 header压缩:
HTTP/2 没使用常见的 gzip 压缩方式来压缩头部,而是开发了 HPACK 算法,HPACK 算法主要包含三个组成部分:
静态字典;
动态字典;
Huffman 编码(压缩算法)
客户端和服务器两端都会建立和维护「字典 」,用长度较小的索引号表示重复的字符串,再用 Huffman 编码压缩数据,可达到 50%~90% 的高压缩率 。静态表是保存在 http2框架里的。
多路复用分侦(server push):HTTP 2.0 其实是将三个请求变成三个流,将数据分成帧,乱序发送到一个 TCP 连接中。将一个请求变成一个流,然后再将流拆分成侦,然后这些侦是可以混杂在一起进行发送。
服务端主动发送:可以在用户请求 html 时,可以主动的推送 css 资源,一次请求,多次发送。
推荐阅读:
https://zhuanlan.zhihu.com/p/352626472
https://zhuanlan.zhihu.com/p/359920955
2.4 http3.0 QUIC和之前的不同
http多是基于 TCP 的传输,因为 HTTP 2.0 也是基于 TCP 协议的,TCP 协议在处理包时是有严格顺序的。当其中一个数据包遇到问题,TCP 连接需要等待这个包完成重传之后才能继续进行。虽然 HTTP 2.0 通过多个 stream,使得逻辑上一个 TCP 连接上的并行内容,进行多路数据的传输,然而这中间并没有关联的数据。一前一后,前面 stream 2 的帧没有收到,后面 stream 1 的帧也会因此阻塞。
基于 UDP 自定义的类似 TCP 的连接:
一条 TCP 连接是由四元组标识的,分别是源 IP、源端口、目的 IP、目的端口。ip改变之后连接断开
QUIC 自己的逻辑里面维护连接的机制,不再以四元组标识,而是以一个 64 位的随机数作为 ID 来标识,而且 UDP 是无连接的,所以当 IP 或者端口变化的时候,只要 ID 不变,就不需要重新建立连接。
重发:
tcp的重发是有缺陷的,当我们如果一个包,由于网络堵塞,发送失败,进行重传之后,然后我们收到包之后,不知道应该如何计算往返时间,不利于我们拥塞控制。

这里加入了,偏移量和id,重发之后加1即可。
多路复用:
有了自定义的连接和重传机制,我们就可以解决上面 HTTP 2.0 的多路复用问题。同 HTTP 2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求。但是,QUIC 是基于 UDP 的,一个连接上的多个 stream 之间没有依赖。这样,假如 stream2 丢了一个 UDP 包,后面跟着 stream3 的一个 UDP 包,虽然 stream2 的那个包需要重传,但是 stream3 的包无需等待,就可以发给用户。
流量控制技术
在 TCP 协议中,接收端的窗口的起始点是下一个要接收并且 ACK 的包,即便后来的包都到了,放在缓存里面,窗口也不能右移,因为 TCP 的 ACK 机制是基于序列号的累计应答,一旦 ACK 了一个序列号,就说明前面的都到了,所以只要前面的没到,后面的到了也不能 ACK,就会导致后面的到了,也有可能超时重传,浪费带宽。
只要收到的,就进行确认,因为后面的到了,前面的肯定已经发送,所以我们可以移动窗口,等待确认前面的和重发即可。
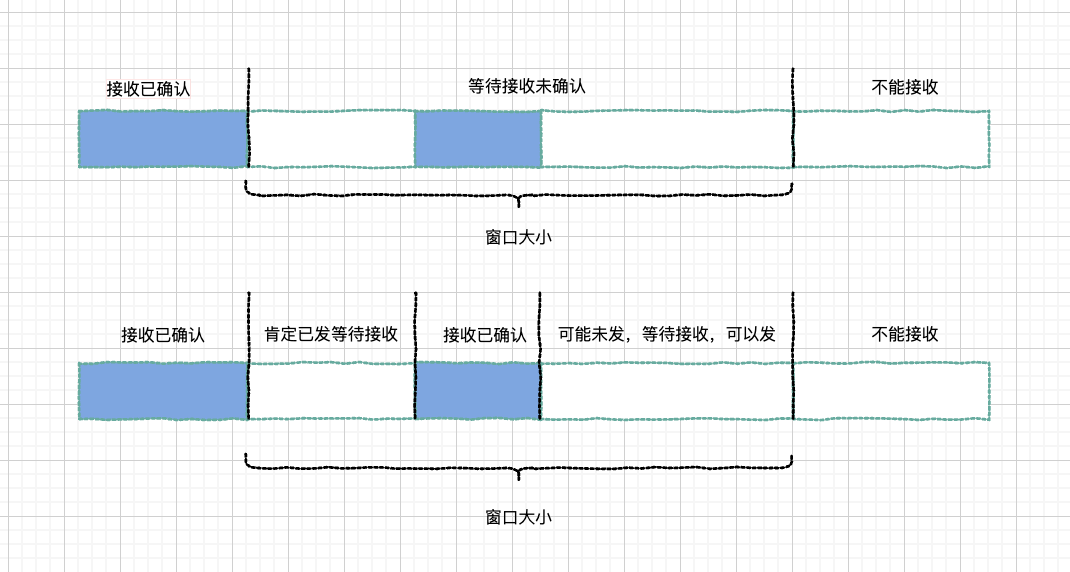
推荐阅读:https://zhuanlan.zhihu.com/p/32553477
2.5 HTTP的缺点
明文传输
没有校验,有可能被篡改
没有验证通信方身份
HTTPS采用混合加密机制,位于HTTP/TCP之间,主要为高层协议服务。
2.6 HTTP请求过程
在浏览器输入网址显示页面的过程
1.查询浏览器缓存,如果有直接访问
2.查询本地host文件,查询本地缓存,或者使用cmd,使用ipconfig /displaydns 命令查询
3.向DNS服务器发送DNS请求,查询本地DNS服务器(此时用到的是递归查询),这其中用的是UDP的协议
4.本地域名服务器会向根域名服务器发送一个请求,如果根域名服务器也不存在该域名时,
5.本地域名会向顶级域名服务器的下一级DNS服务器发送一个请求,依次类推下去。直到最后本地域名服务器得到google的IP地址并把它缓存到本地,供下次查询使用。(上诉的迭代方式是迭代查询)
6.此时我们已经知道了ip地址,及其默认的端口号,http默认的是80端口,https默认的是https端口
7.我们首先会尝试使用http建立socket连接,三次握手之后,开始传送数据,如果是http的话,那么则接收数据,如果不是http,是https则会返回 3开头的重定向,将端口号从 80 端口改成 443 端口,并四次挥手断开之前的连接。
8.再来一遍三次握手,此时还会采用SSL的加密技术来保证传输数据的安全性,保证数据传输过程中不被修改或者替换之类的
9.沟通好双方使用的认证算法,加密和检验算法,在此过程中也会检验对方的CA安全证书。
10.连接完毕,开始传输数据
这里还有很多细节,比如通过ip地址和子网掩码判断是否在同一子网,报文每一跳的情况等。还有 DNS 解析时,递归查询和迭代查询使用哪个传输层协议等,答的尽量细一些。
推荐阅读:https://blog.csdn.net/ailunlee/article/details/90600174
2.7 聊聊HTTPS
HTTPS 是以安全为目标的 HTTP 通道.
在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性 。HTTPS 在HTTP 的基础下加入SSL,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL。
HTTPS使用的是443端口,HTTP是80端口,HTTPS比HTTP多了四次握手的过程所以效率有所降低,大概只有HTTP的1/10。HTTPS则是为了来解决HTTP明文传输,没有检验,有可能被篡改,无法验证对方身份的情况。
HTTPS原理也会考察,而且是高频考点,大家可以看下下面这两个文章
推荐阅读:
https://blog.csdn.net/xiaoming100001/article/details/81109617/
